Lessons from Vibe Coding with Phoenix
•
17 September 2025
•
17 mins
I’ve been head-down working on pipie.io (more on that later). It’s built with Elixir, Phoenix and LiveView. All the good stuff. Of course I’m doing it with heavy use of Claude Code. Or, as the kids would say, vibe coding.
Vibe coding, definitely feels more dynamic, and far faster, but sometimes that doesn’t feel as clear cut as you would like. The golden path of it is amazing:
Build me an index page that includes monitors the gitlab pipelines that we’ve got stored in the database. You might need to hook into the webhooks to get currently running status. Keep the page up to date with a live view/presence. Go!
It then goes off does it’s thing and creates a really great first cut of exactly what you asked for. It has used the test-engineer agent tools to build a heap of unit tests (slightly overfitted) and things are great. It’s got a solid understanding of the right database changes to make including indexes and constraints.
But are they? Is it built well? Is it going to cause the next round of changes to take us back to the good old days of index.php being 7000 lines of code long?
Now, it seems like magic, mind-blowing magic, but as you work with these agents longer and longer you realise that they are quite predictable and guiding that predictability is the key to making it work.
I’m going outline a few techniques below, that are actually age-old techniques that are more important today than ever. To practice what I preach, and to help with YOUR context the techniques are:
- Utilise
@moduledocto make it easier to manage context. - Iterate on your development process with constant tweaking of
AGENTS.md - Utilise worktrees and the included scripts to manage multiple streams of work.
First, a little bit on context.
Context
The key thing to work with, in fact, the only thing that drives an agent is context. What is context and why is it important?
The way an LLM works is it reads all the words (actually tokens) in it’s context window and then decides what the next word to write is. Simple. There is a ridiculously complicated neural network figuring out WHAT the next word to write is behind that, but from where you are sitting that’s all you need to know.
This suggests our key thing is to control what all the previous words are. These agents are building out their context windows more and more with each release, but as they grow, there is the ever increasing problem of signal:noise. Keeping high signal is key.
The agents, have different ways of managing all the information in your codebase. Personally, I like Claude’s approach which is very similar to how I operate, lots of grepping, finding the correct files and generally using pretty lo-fi technology. Cursor uses a semantic search capability, which sometimes doesn’t quite hit the mark.
Nonetheless, it finds the files it thinks are important and loads them into it’s context window. It then summarises all of that into a clear TODO list or a plan, which then proposes edits or tools to use and then does it’s work.
It utilises TODOs to allow it to manage it’s context window. It’s important to know that the interface ie what is presented to you the user and the context, are not the same. You can view it all, but there’s a lot of data flowing so the implementors of the agents hide away a lot.
Documentation
So how can we leverage this? Well the great thing about this is that unlike myself, these agents READ THE FUCKING MANUAL. When they load up a file, they read it and all of it’s documentation.
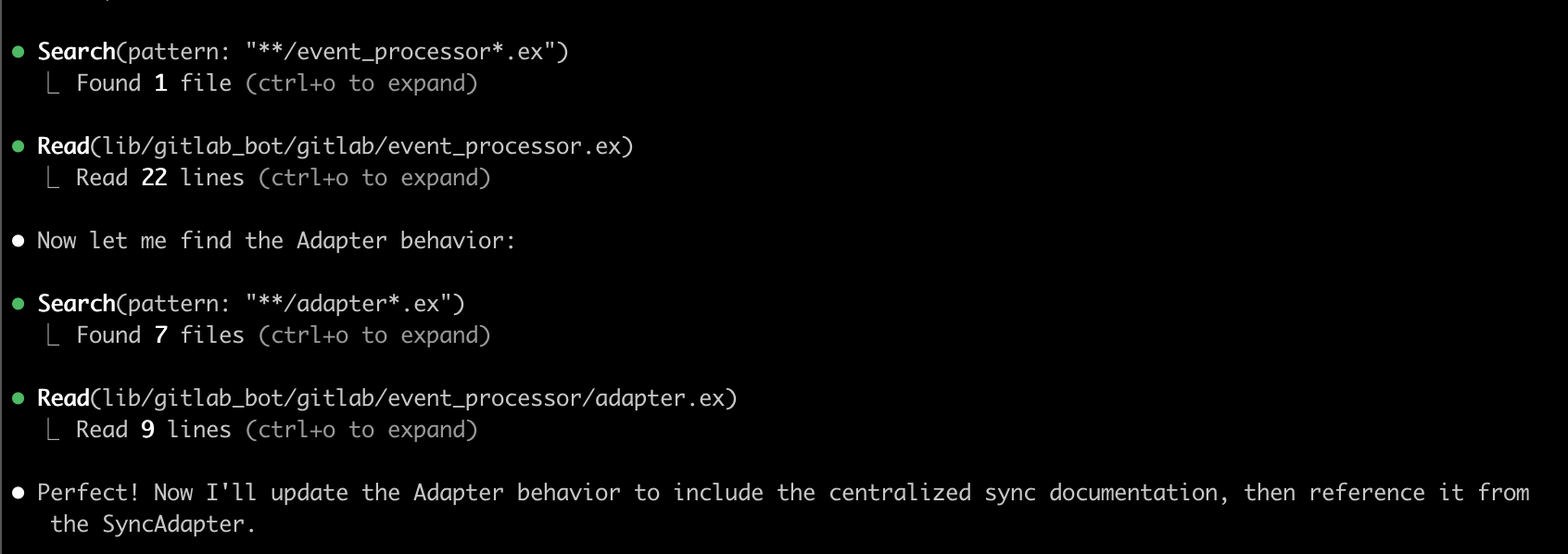
So we can leverage this, by something that has been around since the dawn of time, documentation! We can describe at the top of a module, why it exists, what it’s intent is and how to interact with it. We can reference other modules that this usually interacts with, and let the agent build it’s plan by what we tell it in this documentation.
@moduledoc """
Behavior for GitLab webhook event processors.
## Full Sync Architecture
**CRITICAL**: All adapter implementations must maintain a full sync pattern.
When processing any GitLab event, all related entities must be kept up to date
to maintain data consistency across the system.
### Key Requirements:
1. **Cross-Entity Consistency**: Updates to one entity (MR, Pipeline, Build) must
propagate to all related entities
2. **Status Synchronization**: Status changes must update all dependent records
3. **Real-time Updates**: All changes must broadcast to UI dashboards
4. **Order of Operations**: Process entities before updating cross-references
to prevent race conditions
### Implementation Guidelines:
Future adapter implementations must:
- Consider MR ↔ Pipeline ↔ Build relationships
- Update all relevant status fields across related entities
- Maintain broadcast consistency for real-time UI updates
- Follow the established processing order to prevent data overwrites
See `GitlabBot.Gitlab.EventProcessor.SyncAdapter` for the reference implementation.
"""
This is critical. Without this, it’s makes random decisions about where something should go. Sometimes it will be in the model, sometimes it will create it’s own module other times at the right context layer.
There’s a complaint with LLMs that they are just stochastic character generators, this could be a problem, except we get to rig the dice.
There’s nothing new about this, good documentation is good engineering. There’s definitely been a school of thought that comments are not necessary, because good method names and variable names should do everything that’s needed. That’s not what this is documentation has always been valuable. It’s just more valuable than ever, cause it gets read more.
Now the great thing is, you don’t even need to write it yourself, you can ask the LLM to do it.
Process
Every great engineer I’ve ever worked with has a really strong process. Each person’s is different, some people like to work on paper a lot, others like to scratch around the edges, fix some bugs related to the work to get them in the zone (build context if you will) but as the months and years pass by the engineer always works the same way, it evolves and changes, but it’s theirs and it is repeatable.
And our LLM tools are the same. There’s a loop as part of the overall agentic system architecture, but we get to control the engineering process, more than you might think. This takes the form of an AGENTS.md file and the associated sub-agents and commands that go with it. This file is the “system prompt” which the agent reads in as the first thing it does when it wakes up each day and sets not only it’s processes but it’s raison d’etre.
So, as an agentic engineer, we need to utilise this as our primary tool to make it work better. This will always be an iterative process, and the agents themselves have different modalities eg, planning mode, different models which comes down from the agent itself. We do however control how it does the work.
So I’ve been iterating on a few different approaches:
-
Design & ideation mode. I’ve been sending up “PRDs” to the LLM for it to outline the actual requirements are BEFORE it builds. I’ve been getting the agent to store these in Github separately to the code, and then I can read it on the tram, and think about it. Make comments and then ask the LLM to read my comments and update the PRD.
This can include acceptance tests and criteria. Though I don’t think I’ve quite got this part of it working that well.
- Planning mode. Ensure that first and foremost the agent focuses and consults with me about the architecture of the code. ie. where should we place the different concerns. If the documentation is write, it has a fighting chance to get this right, but it’s important so ensure it collaborates.
- Database design. Having a separate database-engineer agent which has context about what is important when it comes to database design. Over time you can tweak the agent without affecting the broader flow.
- Implementation. I’ve been experimenting with different approaches of TDD/BDD and test-first vs. asking it to write tests afterwards. I’m not sure which of these approaches actually works better. You can definitely end up with the agent spending a lot of time fixing tests with sub-optimal fixes because it struggles to “zoom out” and just fix the single line that’s breaking all the tests.
-
Development mode. When I work I have 2 modes, a “development mode” where I poke around with the dev server, and interact with it in an exploratory loop, utilise the long-lived database to explore, and a TDD/implementation loop where I focus more on what will be the final implementation with tests and so forth.
I’ve been working in a similar way with the agents. Keeping a trail of the real events I receive from Gitlab/Slack and then telling the agent to look in the database. You can take this to the next level and utilise a browser MCP to have the agent interact with the browser, but I haven’t relinquished this much control – yet.
Git (and worktrees)
One of the issues you run into quickly is running multiple branches – you end up wanting to work on a few things in parallel. The recommendation is to use git worktrees. This works by checking out your branch into a different folder, but sharing your git operations. It’s a pretty simple approach you run the command git worktree add -b feature/add-github-webhook ../add-github-webhook and it creates a new branch and a new folder.
But the minute you try to run multiple servers or the same tests side-by-side you get clashes. The agent runs rough-shod over your other branch. So you need to segregate them. Docker and devcontainers would be one approach, but I’ve been experimenting with a simple setup of making them run on different databases and ports based on the branch you are on.
So I’ve made some simple changes to my Phoenix setup to support multiple projects running on the same machine. It takes a hash of the project name and allocates a stable port number. (I currently have a small pool cause of some Cloudflare forwarding to the ports and OAuth callbacks). I’ve attached a diff below.
diff --git a/config/config.exs b/config/config.exs
index 8023e4c..ae0cd52 100644
--- a/config/config.exs
+++ b/config/config.exs
@@ -7,6 +7,16 @@
# General application configuration
import Config
+# Get deterministic port based on git branch
+git_branch = case System.cmd("git", ["branch", "--show-current"], stderr_to_stdout: true) do
+ {branch, 0} -> String.trim(branch)
+ _ -> "main"
+end
+dev_port = case git_branch do
+ branch when branch in ["main", "master"] -> 5000
+ branch_name -> 5001 + rem(:erlang.phash2(branch_name), 10)
+end
+
config :gitlab_bot, :scopes,
user: [
default: true,
@@ -46,7 +56,8 @@ config :gitlab_bot, GitlabBotWeb.Endpoint,
layout: false
],
pubsub_server: GitlabBot.PubSub,
- live_view: [signing_salt: "aaaaaaaa"]
+ live_view: [signing_salt: "aaaaaaaa"],
+ http: [port: dev_port]
# Configures the mailer
#
diff --git a/config/dev.exs b/config/dev.exs
index 427c3f1..699e38d 100644
--- a/config/dev.exs
+++ b/config/dev.exs
@@ -1,11 +1,25 @@
import Config
+# Get deterministic port and database based on git branch
+git_branch = case System.cmd("git", ["branch", "--show-current"], stderr_to_stdout: true) do
+ {branch, 0} -> String.trim(branch)
+ _ -> "main"
+end
+dev_port = case git_branch do
+ branch when branch in ["main", "master"] -> 5000
+ branch_name -> 5001 + rem(:erlang.phash2(branch_name), 10)
+end
+db_suffix = case git_branch do
+ branch when branch in ["main", "master"] -> ""
+ branch_name -> "_#{rem(:erlang.phash2(branch_name), 999)}"
+end
+
# Configure your database
config :gitlab_bot, GitlabBot.Repo,
username: "postgres",
password: "postgres",
hostname: "localhost",
- database: "gitlab_bot_dev",
+ database: "gitlab_bot_dev#{db_suffix}",
stacktrace: true,
show_sensitive_data_on_connection_error: true,
pool_size: 10
@@ -20,7 +34,7 @@ config :gitlab_bot, GitlabBotWeb.Endpoint,
# Binding to loopback ipv4 address prevents access from other machines.
# Change to `ip: {0, 0, 0, 0}` to allow access from other machines.
url: [host: "glbot.wakeless.net", port: 443, scheme: "https"],
- http: [ip: {127, 0, 0, 1}, port: 5000],
+ http: [ip: {127, 0, 0, 1}, port: dev_port],
check_origin: false,
code_reloader: true,
debug_errors: true,
diff --git a/config/test.exs b/config/test.exs
index 767ea82..4a187c9 100644
--- a/config/test.exs
+++ b/config/test.exs
@@ -1,5 +1,16 @@
import Config
+# Get deterministic values based on git branch
+git_branch = case System.cmd("git", ["branch", "--show-current"], stderr_to_stdout: true) do
+ {branch, 0} -> String.trim(branch)
+ _ -> "main"
+end
+
+db_suffix = case git_branch do
+ branch when branch in ["main", "master"] -> ""
+ branch_name -> "_#{rem(:erlang.phash2(branch_name), 999)}"
+end
+
# Only in tests, remove the complexity from the password hashing algorithm
config :bcrypt_elixir, :log_rounds, 1
@@ -12,7 +23,7 @@ config :gitlab_bot, GitlabBot.Repo,
username: "postgres",
password: "postgres",
hostname: "localhost",
- database: "gitlab_bot_test#{System.get_env("MIX_TEST_PARTITION")}",
+ database: "gitlab_bot_test#{db_suffix}#{System.get_env("MIX_TEST_PARTITION")}",
pool: Ecto.Adapters.SQL.Sandbox,
pool_size: System.schedulers_online() * 2
@@ -21,7 +32,12 @@ config :gitlab_bot, GitlabBot.Repo,
#
#
#
-port = String.to_integer("400#{System.get_env("MIX_TEST_PARTITION") || 2}")
+base_port = case git_branch do
+ branch when branch in ["main", "master"] -> 5000
+ branch_name -> 5001 + rem(:erlang.phash2(branch_name), 10)
+end
+port_offset = String.to_integer(System.get_env("MIX_TEST_PARTITION") || "0")
+port = base_port + 100 + port_offset
config :gitlab_bot, GitlabBotWeb.Endpoint,
http: [ip: {127, 0, 0, 1}, port: port],
Like it? Share it!